Categories
Artificial intelligence
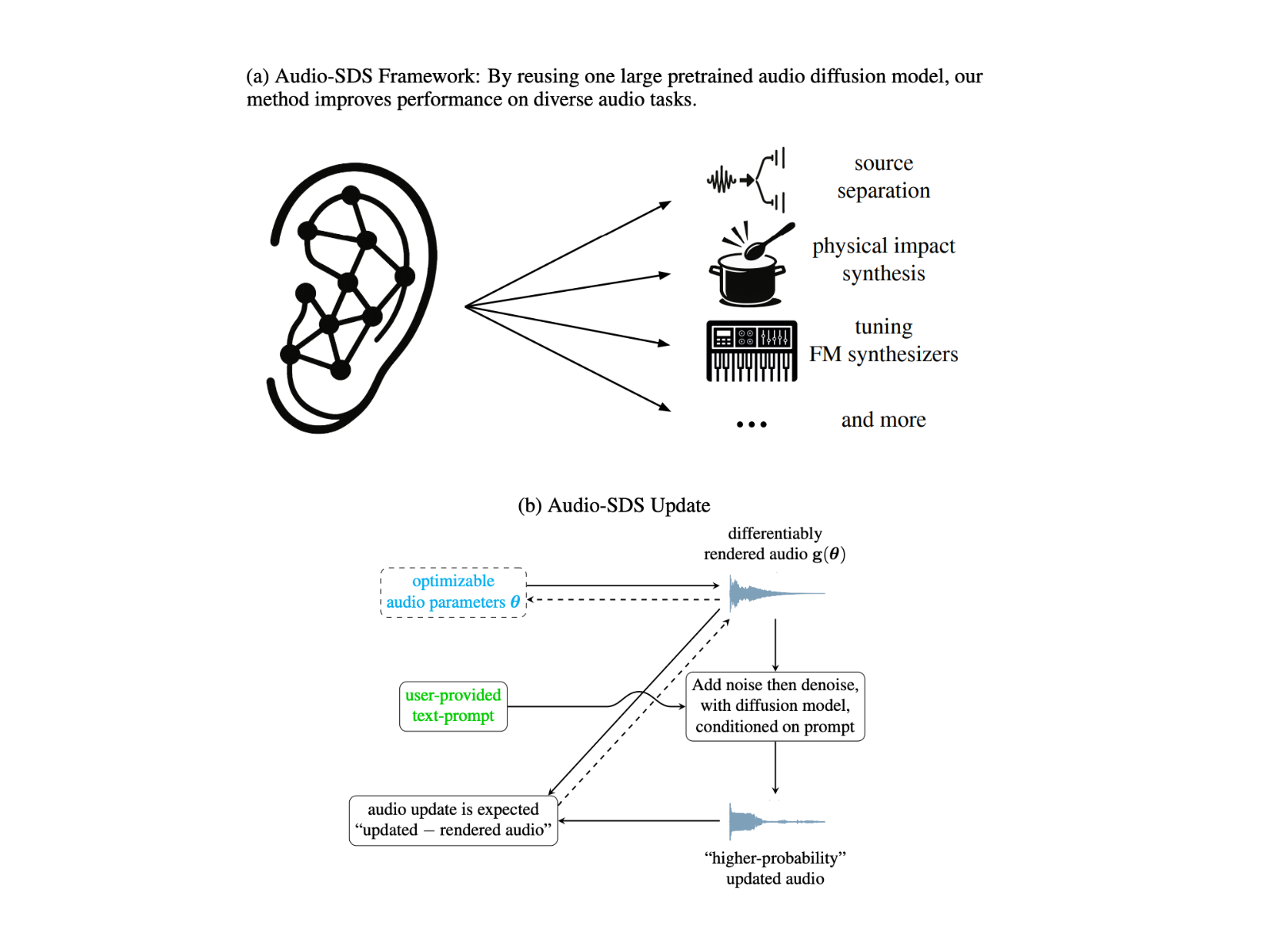
NVIDIA AI Introduces Audio-SDS: A Unified Diffusion-Based Framework for Prompt-Guided Audio Synthesis and Source Separation without Specialized Datasets
[ad_1] Audio diffusion models have achieved high-quality speech, music, and Foley sound synthesis, yet they predominantly excel at sample generation rather than parameter optimization.…
Read More