Categories
Artificial intelligence
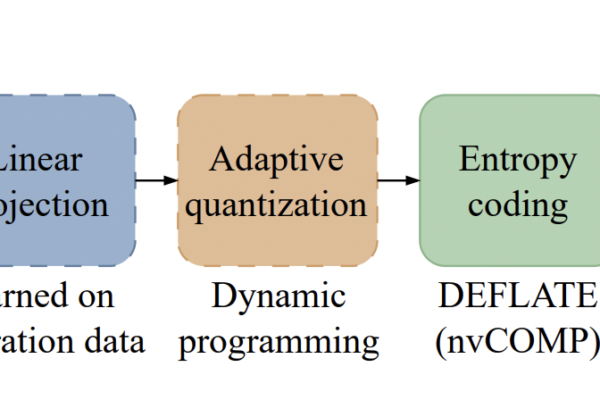
NVIDIA Researchers Introduce KVTC Transform Coding Pipeline to Compress Key-Value Caches by 20x for Efficient LLM Serving
Serving Large Language Models (LLMs) at scale is a massive engineering challenge because of Key-Value (KV) cache management. As models grow in size and…
Read More