[ad_1]
Today we are going to look at pix2pix architecture which changes everything. We have been talking about different architectures are able to do certain tasks well, and if you need a model to handle some other task then you would have to modify the architecture or tweak it a little to get the desired output. Pix2pix promises to have generalized this solution to many of those problems. All you have to do is change the training data, run a training iteration and the parameters will have been adjusted to your custom task.
We then come to a question, how did they do that? Think about it, if GANs are able to generate an approximate output based on training data from random noise, then pix2pix architecture has to be doing something which is mapping some input to the training image. It is conditioning the model to measure losses with respect to the training image, the only thing is, input to the model is not random noise anymore, it could be an outline or a drawing or some shape which resembles even remotely to the training data.
Conversations happening at the back end:
User: Gives an input of an outline of a cat.
Generator of cGAN: What the hell is that?
Discriminator: I think it’s a cat, kind of…
Generator: I see, let me see if i can create something.
Few moments later…
Generator: How’s this?
Discriminator: What is this? Is this supposed to be a cat?
Generator: What? I think this is my best work…
Discriminator: Really? May be you were better when you were just creating random noise at GAN.
Generator: That’s harsh… let me try again…
Generator: How’s this one?
Discriminator: I think, better…, but don’t overdo yourself, we just have to be as good as the user’s sketch. I wish if there was a way we could train the user, because i have seen better cats.
Generator: Are you British?
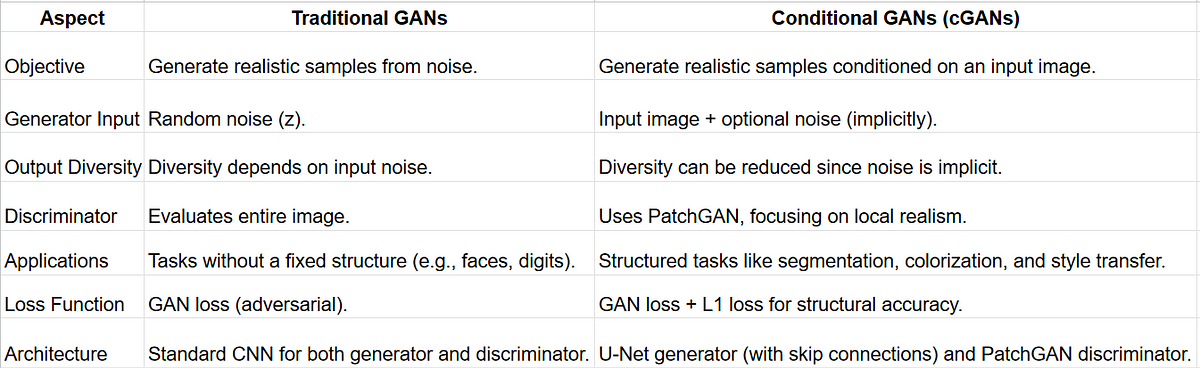
What cGANs are doing differently?

Below are some key things which pix2pix is doing to enhance it’s performance:
Structured Generation:
- In tasks like translating semantic maps to images or edges to objects, cGANs leverage the input image as a structural guide, producing outputs aligned with the input structure.
Local Realism with PatchGAN:
- Evaluating realism on smaller patches allows the model to focus on texture details rather than global consistency, which is often sufficient for tasks like photo generation.
Improved Detail Preservation:
- Skip connections in the U-Net generator ensure that low-level spatial features are preserved, avoiding the loss of fine details often seen in traditional GANs.
And below are the two loss functions compared of GANs and cGANs:
Traditional GAN loss:

cGAN loss (conditioned on x):

L1 loss:

Total loss:

- The generator takes an input image and produces a corresponding output image.
- The discriminator is given: The real pair: Input image + ground truth output image. The fake pair: Input image + generated output image.
- The discriminator learns to distinguish real pairs from fake pairs, while the generator learns to fool the discriminator into believing its outputs are real.
[ad_2]