Practical Implementation
One of KZImputer’s strongest advantages is its scikit-learn compatibility. The implementation follows familiar sklearn conventions, making it effortless to integrate into existing machine learning pipelines.
Here’s how simple it is to use:
from src.custom_imputer import KZImputer
import numpy as np# Your time series data with missing values (represented as NaN)
data = np.array([1.0, 2.0, np.nan, np.nan, 5.0, 6.0, np.nan, 8.0])
# Create and apply the imputer
imputer = KZImputer()
data_imputed = imputer.fit_transform(data.reshape(-1, 1))
The method requires no complex hyperparameter tuning and adapts automatically to your data’s characteristics.
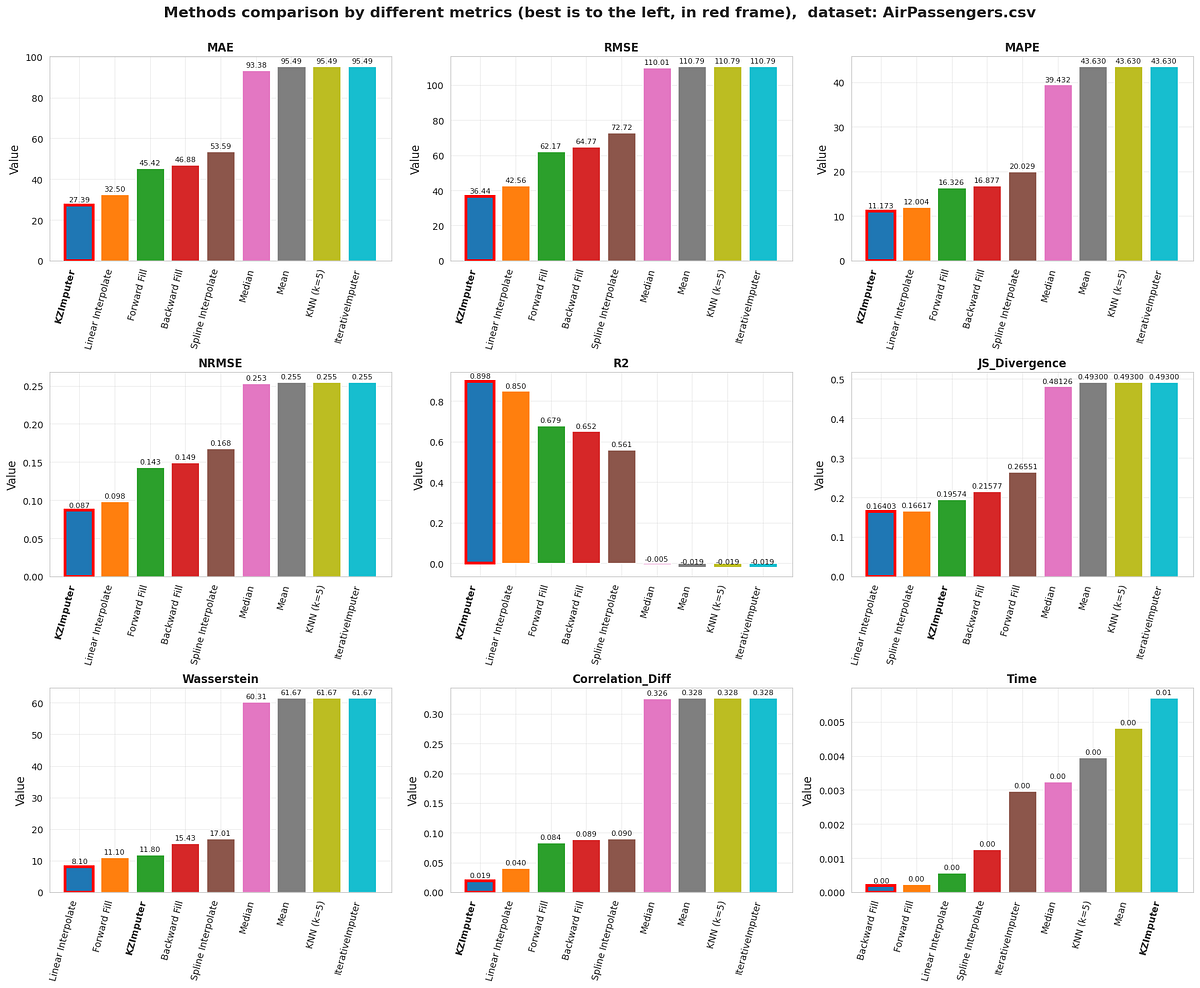
Methods comparison by 8 different metrics (other visualization, after KZImputer optimization):
Table comparison of 8 different methods with ranking:
When Should You Use KZImputer?
KZImputer is particularly well-suited for:
- Univariate time series with temporal dependencies
- Short to medium gaps where context matters
- Smooth or semi-smooth data like sensor readings, financial data, or environmental measurements
- Scenarios requiring interpretability where you need to understand how values were imputed
- Pipelines requiring sklearn compatibility for seamless integration
For extremely irregular data or very long gaps, more sophisticated deep learning approaches might be necessary. However, for the majority of real-world time series imputation tasks, KZImputer offers an excellent balance of performance, simplicity, and adaptability.
The Bigger Picture
The development of KZImputer reflects a broader trend in data science: moving beyond generic solutions toward context-aware, adaptive methods. As datasets grow larger and more complex, algorithms that can intelligently adjust their behavior based on data characteristics will become increasingly valuable.
Missing data imputation might not be the most glamorous topic in machine learning, but it’s one of the most practically important. Poor imputation can cascade through your entire analytical pipeline, leading to biased models and unreliable predictions. Getting it right matters.
Getting Started
The complete implementation is available as open-source on GitHub, with a comprehensive Jupyter notebook demonstrating the method’s performance across multiple datasets. The repository includes:
- Full source code with detailed documentation
- Benchmark comparisons with established methods
- Visualizations of imputation results
- Ready-to-use examples
Whether you’re working with industrial sensor data, healthcare time series, or any other domain with missing values, KZImputer provides a practical, theoretically grounded solution to improve your data quality.
Looking Forward
As time series analysis continues to grow in importance across industries — from IoT sensor networks to healthcare monitoring systems — methods like KZImputer that intelligently handle missing data will become essential tools in every data scientist’s toolkit.
The key insight is simple but powerful: not all missing values are created equal. Where a gap occurs and how large it is should fundamentally influence how we fill it. KZImputer embodies this principle in an accessible, practical implementation.