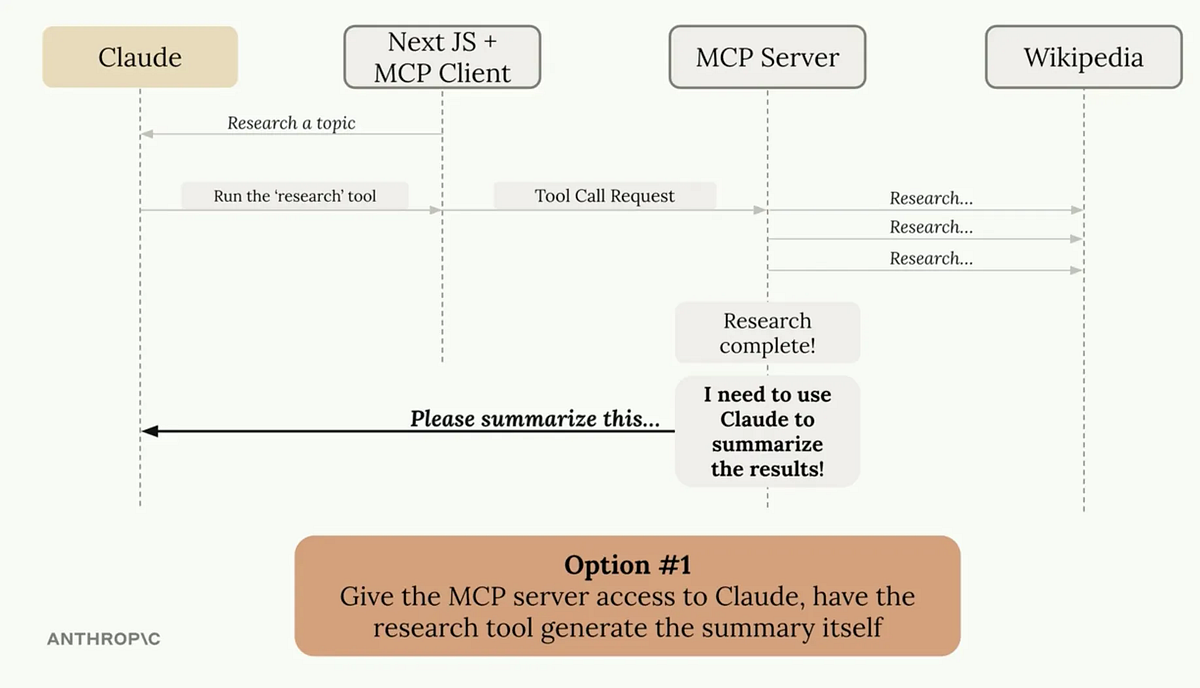
The Sampling Solution
Sampling flips this model on its head. Instead of the server calling the AI model directly, it asks the client to do it. Here’s how it works:
- The server gathers necessary data (like Wikipedia articles or documentation)
- The server prepares a prompt for text generation
- The server sends a sampling request to the client
- The client calls Claude with the prompt
- The client returns the generated text to the server
- The server includes the generated text in its response
Why This Matters
This architectural shift delivers three major benefits:
- Reduced complexity: No direct model integration needed on the server
- Cost transfer: The client pays for tokens, not the server
- No credential management: Server doesn’t need to maintain AI provider credentials
Implementation Example
On the server side, requesting sampling is straightforward:
@mcp.tool()
async def summarize(text_to_summarize: str, ctx: Context):
prompt = f"""Please summarize the following text: {text_to_summarize}"""
result = await ctx.session.create_message(
messages=[SamplingMessage(
role="user",
content=TextContent(type="text", text=prompt)
)],
max_tokens=4096,
system_prompt="You are a helpful research assistant"
)
if result.content.type == "text":
return result.content.text
else:
raise ValueError("Sampling failed")The client handles the actual AI call:
async def sampling_callback(context: RequestContext, params: CreateMessageRequestParams):
# Call Claude using Anthropic SDK
text = await chat(params.messages)
return CreateMessageResult(
role="assistant",
model=model,
content=TextContent(type="text", text=text),
)# Pass callback on client session init:
async with ClientSession(read, write, sampling_callback=sampling_callback) as session:
await session.initialize()Sampling is ideal for public MCP servers where you want to provide powerful AI capabilities without bearing the infrastructure and cost burden.


