5. Predicting Outcome Distributions from Hidden States
The Hypothesis
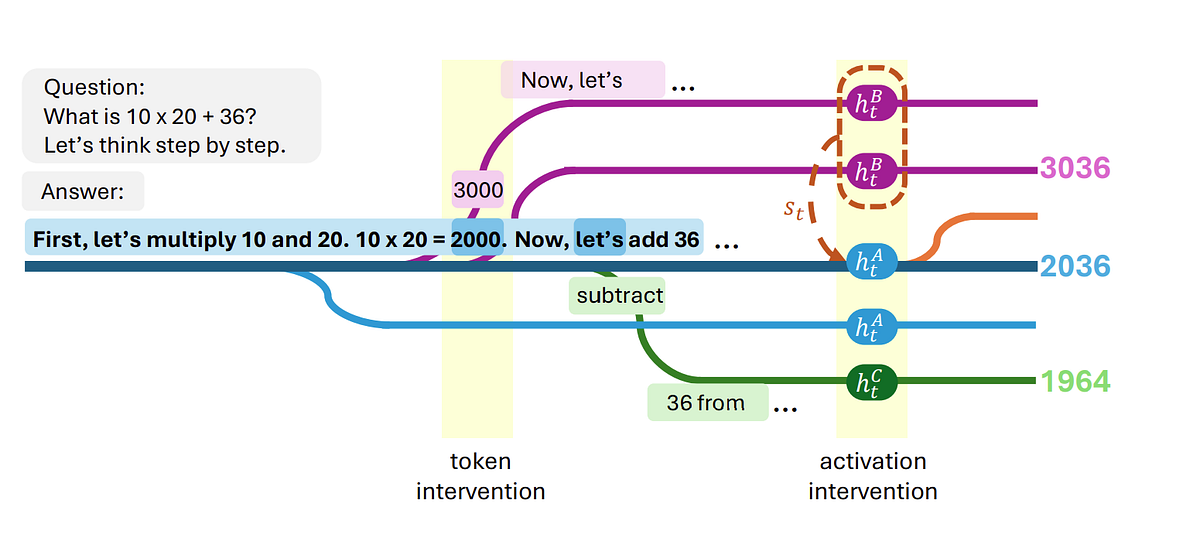
The text up to token t contains semantic information about the eventual answer. But do hidden states contain EXTRA information beyond the text?
Test: Train linear probes to predict oₜ from:
- hₜ: Llama-3.2’s own activations at token t
- h’ₜ: Gemma-2 2B’s activations on the same text (different model)
If both perform equally, then the text alone is sufficient. If Llama’s activations perform better, they encode model-specific decision-making information.
Results
KL LOSS RESULTS (Lower is Better)
Llama-3.2 (original): 0.11 [Best at Layer 8] Gemma-2 (different): 0.19 [Best at Layer 8] Majority baseline: 0.85 Random baseline: 1.53
Key Insight: Llama-3.2’s own hidden states predict its outcome distribution 42% more accurately than Gemma-2’s states, proving model-specific decision-making information exists beyond surface text.
STEERING CORRELATION RESULTS
Main example (Figure 2): R = 0.57 Average across 4 examples: R = 0.64 Interpretation: Moderate correlation between uncertainty and steerability — models are easier to redirect when they’re still deciding.
EXPERIMENTAL SCOPE SUMMARY
Model Tested: Llama-3.2 3B Instruct, Datasets: GSM8k, AQuA, GPQA (4 uncertain examples total) Samples per Example: 500 generations for steering vectors, 10 continuations for testing Computational Cost: Forking Paths Analysis requires millions of tokens per example
LAYER PERFORMANCE PATTERN
Best predictive layers: 6–10 (middle layers) ,Steering vector layers: 12+ (later layers), Pattern: Uncertainty representation peaks mid-network, while answer commitment signals emerge later.
Key Insights:
- Both models beat baselines: The reasoning chain text is predictive
- Llama’s own activations are 42% better (0.11 vs 0.19)
- Middle layers matter: Layers 6–10 are most predictive (where high-level reasoning is processed)
- Later layers diverge: Gemma’s performance degrades in deep layers, suggesting model-specific processing
What This Means
The hidden states contain a “decision signature” — information about the model’s internal uncertainty and planning that isn’t explicit in the text. This is evidence that models do represent alternate paths, not just the current one.


